ViT code Review
Vision Transformer(ViT)의 코드는 해당 페이지를 참조했다.
또한 영어로 글 쓰는 것에 익숙해지기 위해 코드 리뷰는 영어로 써보았다.
전체적인 리뷰와 보면서 들었던 궁금증과 이에 대한 답변은 한글로 썼으니, 한글이 익숙한 분들은 해당 부분만 보아도 좋을 것 같다.
Code Review
Import Library
1
2
3
4
5
import torch
from torch import nn
from einops import rearrange, repeat
from einops.layers.torch import Rearrange
The ‘einops’ is a library that changes dimensions intuitively.
FeedForward
1
2
3
4
5
6
7
8
9
10
11
12
13
14
class FeedForward(nn.Module):
def __init__(self, dim, hidden_dim, dropout = 0.):
super().__init__()
self.net = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(hidden_dim, dim),
nn.Dropout(dropout)
)
def forward(self, x):
return self.net(x)
It’s a simple FFN with 2 layers, and it uses LayerNorm and GELU.
Attention
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
class Attention(nn.Module):
def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):
super().__init__()
inner_dim = dim_head * heads
project_out = not (heads == 1 and dim_head == dim)
self.heads = heads
self.scale = dim_head ** -0.5
self.norm = nn.LayerNorm(dim)
self.attend = nn.Softmax(dim = -1)
self.dropout = nn.Dropout(dropout)
self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)
self.to_out = nn.Sequential(
nn.Linear(inner_dim, dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self, x):
x = self.norm(x)
qkv = self.to_qkv(x).chunk(3, dim = -1)
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d',
h = self.heads), qkv)
dots = torch.matmul(q, k.transpose(-1, -2)) * self.scale
attn = self.attend(dots)
attn = self.dropout(attn)
out = torch.matmul(attn, v)
out = rearrange(out, 'b h n d -> b n (h d)')
return self.to_out(out)
The ‘to_qkv’ function creates a linear layer from input dim to 3 x inner dim. Inner dim is the product of heads and dim_head. After this function, use the torch.chunk function to divide it into 3 tensors with the same dimensions.
And use the rearrange function to change the dimension ‘n (h d)’ to ‘h n d’. The ‘h’ is the number of heads, the ‘d’ is the dimension of heads. And the ‘n’ is the number of input patches.
The ‘dots’ is a scaled matrix multiplication of q and transposed k. It becomes a tensor of dimension ‘b h n n’ , and the softmaxed output of it is the attention score. Interestingly, they use a dropout layer after the attention score.
Finally, the matrix multiplication of the attention score and v becomes a tensor of dimension ‘b h n d’. And this tensor is arranged to the dimension ‘b n (h d)’, which has the same dimension as ‘qkv’. After a linear layer and a dropout layer, it becomes an attention output of dimension ‘b n dim’.
Transformer
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
class Transformer(nn.Module):
def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.layers = nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
Attention(dim,
heads = heads,
dim_head = dim_head,
dropout = dropout),
FeedForward(dim,
mlp_dim,
dropout = dropout)
]))
def forward(self, x):
for attn, ff in self.layers:
x = attn(x) + x
x = ff(x) + x
return self.norm(x)
In the Transformer class, it uses the ‘nn.ModuleList’ function, which can store pytorch modules. This is different from the ‘nn.Sequential’ function, which has a forward method in it. So, if you are using layers in the ‘nn.Modulelist’, you should use a for loop to feed forward each layer.
Using this ‘nn.Modulelist’ function, we can stack ‘Attention’ and ‘FeedFoward’ layers as much as ‘depth’. And we can add skip-connections between the layers, because they all have the same dimensions.
Finally, the ‘LayerNorm’alized output is returned.
ViT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
class ViT(nn.Module):
def __init__(self, *, image_size, patch_size, num_classes,
dim, depth, heads, mlp_dim,
pool = 'cls', channels = 3, dim_head = 64,
dropout = 0., emb_dropout = 0.):
super().__init__()
image_height, image_width = pair(image_size)
patch_height, patch_width = pair(patch_size)
assert image_height % patch_height == 0 and image_width % patch_width == 0, \
'Image dimensions must be divisible by the patch size.'
num_patches = (image_height // patch_height) * (image_width // patch_width)
patch_dim = channels * patch_height * patch_width
assert pool in {'cls', 'mean'}, \
'pool type must be either cls (cls token) or mean (mean pooling)'
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)',
p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))
self.cls_token = nn.Parameter(torch.randn(1, 1, dim))
self.dropout = nn.Dropout(emb_dropout)
self.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)
self.pool = pool
self.to_latent = nn.Identity()
self.mlp_head = nn.Linear(dim, num_classes)
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
As you can see above, the height and width of the image must be divided by the size of the patch. I thought that the patch should be a square, but it could be a rectangle. It will be a good experience to experiment with the ViT model using a rectangle patch.
The ‘cls_token’ is used for classification, and it has the same dimension with hidden dimension size. By using the repeat function of einops, we can make ‘cls_token’s as much as the batch size. After concatenating ‘cls_tokens’ to the patch embedding of the image, the output becomes dimension of ‘b (n+1) d’. So, we should add ‘pos_embedding’ for all ‘n’ patches and ‘1’ classification token. This is the reason why ‘pos_embedding’ is an ‘(n+1)’ dimension vector.
And we can choose ‘pool’ between ‘cls’ and ‘mean’. The ‘cls’ means that you will use only one classification token for classification, while the ‘mean’ means that you will use the mean of all patches and one classification token for classification.
This is a base code for ViT, so the ‘to_latent’ layer is just an identity function and the ‘mlp_head’ is a simple linear layer. We can modify these layers to improve the performance or to use them for other tasks.
필기 내용
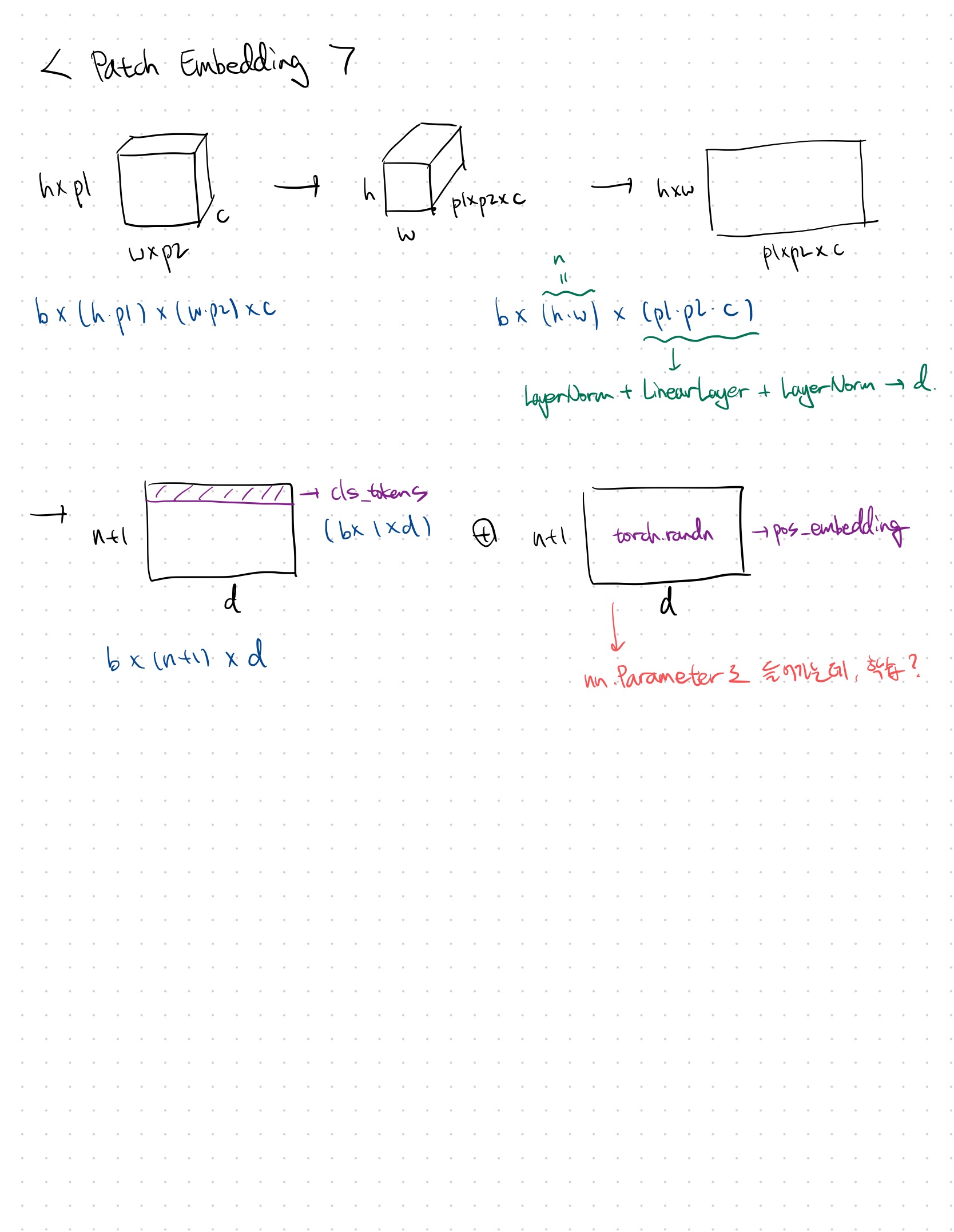 |  |
전체적인 구조 이해를 위해 필기했던 내용이다.
Review
처음으로 코드에 대한 리뷰를 제대로 해보았다. 여태까지는 코드에 대한 전반적인 이해만 하고 활용하기 바빴는데, 세세하게 이해하려고 노력하니 꽤나 시간이 오래 걸렸다.
코드만 보았을 때 전체적인 흐름이 눈에 확 들어오지 않아서 그림을 그려보았는데, 이것이 큰 도움이 되었다. 이후에도 새로운 구조에 대한 코드를 볼 때, 그림을 적극적으로 그려보아야겠다.
또한 영어 공부도 할 겸, 영어로 작성해보았는데 좋은 것 같다. DeepL이라는 사이트를 이용해서 내가 쓴 영어 문장이 어색하지 않은지 피드백을 받으면서 작성했는데 도움이 많이 되었다.
Comments
코드를 보면서 새로웠던 몇가지에 대해서 코멘트를 적어보겠다.
- 패치 임베딩에서 q, k, v를 생성할 때, 하나의 LinearLayer로 간단하게 생성할 수 있다.
- Attention 계산에서 k를 transpose할 때, 마지막 두 차원만 바꿔준다. 그리고 pytorch의 matmul 연산은 마지막 두 차원에 대해 수행한다.
- Positional Encoding을 torch.randn으로 랜덤한 값을 넣어준다.
- CLS token을 패치 개수에 해당하는 차원에 더해준다.
Questions
Head의 dimension의 제곱근으로 attention 결과를 스케일링 해주는 이유?
아마 값이 커져서였던 것 같은데, 정확하게 기억이 나지 않는다.Softmax의 gradient 값들은 확률들의 곱으로 표현되기 때문에 특정 값이 아주 작게 나오는 경우, gradient vanishing 문제가 발생할 수 있다고 한다. 이를 해결해주기 위해 분산을 줄이고자 스케일링한다. 그리고 $q$와 $k$가 모두 랜덤 변수일 때, $q$와 $k$는 $d_k$의 분산을 가지기 때문에 $d_k$로 스케일링 해준다.
ViT에서는 PE도 학습하는건지?
아니면 이 코드에서만 특이하게 랜덤한 값을 집어넣은건지?원래 PE는 sinusoidal 함수로 encoding하여 학습하지 않는다고 알고 있었는데, GPT와 같은 주요한 NLP 모델들은 1d learned encoding을 사용한다고 한다. 그리고 ViT에서의 SOTA도 1d learned encoding을 사용한다고 한다. 1d learned encoding을 absolute PE라고 하고 2d learned encoding을 axial PE라고 하는데, 논문에 따르면 두개의 성능 차이가 없다.
Head의 개수와 차원에 대한 논문이 있었던 것 같은데 뭐였는지 찾아보자.
Rank 관련된 개념으로, 둘의 값을 잘 조정해야 한다는 내용이었던 것 같다.자연어처리에서 문장의 길이를 n, hidden dimension을 d, head의 개수를 h라 하면 각 head가 가지는 dimension의 크기가 d/h가 된다. 이때 이 head size가 n보다 작으면 low-rank bottleneck으로 인해 각 head가 representation power를 잃게 된다. 결론적으로 head size가 n이상은 되어야 각 head가 충분한 표현력을 가지게 된다는 것이다. BERT에서 (# params 는 고정한 상태에서) head size를 늘린다고 성능이 증가하지 않는 것이 이러한 이유이다. 아마 이와 같은 개념으로 비전에서도 head size가 일정 수준 이상으로 커질 경우, 성능이 저하될 것으로 보인다.